

รู้จัก Vector Database: ฐานข้อมูลที่ค้นหาจาก “ความหมาย” ไม่ใช่แค่ Keyword
สรุป Vector Database แบบเข้าใจง่ายในมุม Software Engineer ว่ามันคืออะไร ทำงานยังไง เกี่ยวข้องกับ Embedding, Semantic Search, ChromaDB และ RAG อย่างไร รวมถึงข้อควรระวังเมื่อนำไปใช้จริง
รู้จัก Vector Database: ฐานข้อมูลที่ค้นหาจาก “ความหมาย” ไม่ใช่แค่ Keyword
ช่วงหลังผมเริ่มศึกษาเรื่อง RAG และ AI tools มากขึ้น เลยเจอคำว่า Vector Database บ่อยมาก
ตอนแรกผมเข้าใจง่าย ๆ ว่า Vector Database คือ database สำหรับ AI แต่พอศึกษาเพิ่มขึ้นก็เริ่มเห็นภาพว่า จริง ๆ แล้วมันคือฐานข้อมูลที่ไม่ได้เก็บและค้นหาข้อมูลแบบ SQL ปกติ แต่ใช้การค้นหาจาก “ความหมาย” ของข้อมูลแทน
บทความนี้เป็นโน้ตสรุปความเข้าใจของผมเกี่ยวกับ Vector Database, Embedding, Semantic Search และการนำไปใช้กับ RAG
Vector Database คืออะไร
Vector Database คือฐานข้อมูลที่ใช้เก็บข้อมูลในรูปแบบ Vector Embedding
พูดง่าย ๆ คือ เราเอาข้อมูล เช่น ข้อความ รูปภาพ หรือเสียง ไปผ่านโมเดลที่เรียกว่า Embedding Model เพื่อแปลงข้อมูลนั้นให้กลายเป็นตัวเลขหลายมิติ
ตัวเลขเหล่านี้จะเป็นเหมือน “พิกัด” ของความหมาย
เช่น คำว่า
หมา
สุนัข
dog
ถึงแม้จะเป็นคนละคำ แต่ในเชิงความหมายมันใกล้กัน ดังนั้นเมื่อถูกแปลงเป็น vector แล้ว ตำแหน่งของมันก็ควรอยู่ใกล้กัน
นี่คือจุดที่ต่างจาก keyword search แบบเดิม
Keyword search จะสนใจว่าคำตรงกันไหม แต่ Vector Search จะสนใจว่าความหมายใกล้กันไหม
ทำไม Keyword Search อย่างเดียวถึงไม่พอ
ในระบบค้นหาแบบเดิม ถ้าเราค้นหาคำว่า “สุนัข” ระบบอาจหาเจอเฉพาะข้อมูลที่มีคำว่า “สุนัข”
แต่ถ้าข้อมูลใช้คำว่า “หมา” หรือ “dog” ระบบอาจไม่เจอ ทั้งที่ความหมายใกล้กันมาก
Vector Database แก้ปัญหานี้ด้วยการค้นหาแบบ Semantic Search หรือการค้นหาเชิงความหมาย
ตัวอย่างเช่น
ค้นหา: วิธีดูแลสุนัข
ระบบอาจดึงข้อมูลที่เกี่ยวกับ
อาหารหมา
การเลี้ยงลูกสุนัข
dog care
สัตว์เลี้ยง
ออกมาได้ แม้คำจะไม่ได้ตรงกันทั้งหมด
Vector Embedding คืออะไร
Vector Embedding คือการแปลงข้อมูลให้เป็นตัวเลขหลายมิติ
ตัวอย่างแบบเข้าใจง่าย:
"Backend Developer" → [0.12, -0.55, 0.88, ...]
"Software Engineer" → [0.10, -0.50, 0.81, ...]
"Banana" → [-0.92, 0.13, 0.04, ...]
ถ้าข้อมูลมีความหมายใกล้กัน vector ของมันก็มักจะอยู่ใกล้กัน
Embedding Model ที่ใช้กันทั่วไปมีทั้งแบบ API service เช่น OpenAI Embedding หรือ open source model เช่น Sentence Transformers
สิ่งสำคัญคือ ต้องใช้ Embedding Model ตัวเดียวกันทั้งตอนเก็บข้อมูลและตอนค้นหา
ถ้าตอนเก็บใช้โมเดลหนึ่ง แต่ตอนค้นหาใช้อีกโมเดลหนึ่ง พิกัดของข้อมูลอาจไม่อยู่ใน space เดียวกัน ทำให้ผลลัพธ์เพี้ยนได้
Vector Search ทำงานยังไง
หลังจากข้อมูลถูกแปลงเป็น vector แล้ว การค้นหาจะใช้การวัดความใกล้เคียงระหว่าง vector
วิธีที่เจอบ่อยคือ
Cosine Similarity
Cosine Similarity วัดจาก “ทิศทาง” หรือ “องศา” ของ vector
ถ้า vector สองตัวชี้ไปในทิศทางใกล้กัน แปลว่าความหมายใกล้กัน
จุดเด่นคือไม่ค่อยสนใจขนาดของ vector แต่สนใจทิศทางมากกว่า จึงเหมาะกับการวัด semantic similarity
Euclidean Distance
Euclidean Distance วัดจาก “ระยะห่าง” ระหว่างจุดสองจุด
ถ้าระยะห่างน้อย แปลว่าข้อมูลอยู่ใกล้กัน
วิธีนี้เข้าใจง่ายเหมือนการวัดระยะระหว่างพิกัดบนกราฟ แต่ในโลกจริง vector อาจมีหลายร้อยหรือหลายพันมิติ
Indexing และ ANN
ถ้าข้อมูลมีจำนวนไม่มาก เราอาจเทียบ vector ทุกตัวกับ query ได้โดยตรง
แต่ถ้าข้อมูลมีเป็นแสน เป็นล้าน หรือมากกว่านั้น การไล่เทียบทุกตัวจะช้ามาก
ตรงนี้จึงมีเทคนิคอย่าง ANN หรือ Approximate Nearest Neighbors
แนวคิดคือ แทนที่จะหาคำตอบที่ถูกต้องที่สุดแบบ 100% ระบบจะหาคำตอบที่ใกล้เคียงมากพอ แต่เร็วขึ้นมาก
นี่คือ trade-off ที่สำคัญของ Vector Database
ความเร็วมากขึ้น
แลกกับ
ผลลัพธ์ที่อาจเป็น approximate ไม่ใช่ exact 100%
สำหรับระบบ AI หลายแบบ วิธีนี้ถือว่ายอมรับได้ เพราะสิ่งที่เราต้องการคือข้อมูลที่เกี่ยวข้องมากพอเพื่อส่งต่อให้ LLM ใช้งาน
ChromaDB คืออะไร
ChromaDB เป็น Open Source Vector Database ที่เหมาะกับการเริ่มทดลอง เพราะใช้งานง่ายและ setup ไม่ยาก
เหมาะกับ use case เช่น
- ทดลองทำ Semantic Search
- ทดลองทำ RAG
- ทำ prototype
- ทดสอบ embedding model
- ทำ knowledge base ขนาดเล็ก
ChromaDB รองรับทั้งแบบ in-memory สำหรับทดลอง และแบบ persistent สำหรับเก็บข้อมูลไว้ใช้งานต่อ
ถ้าเป็นงาน production ที่ข้อมูลเยอะมาก หรือมี requirement ด้าน performance สูง อาจต้องพิจารณาเครื่องมืออื่น เช่น Qdrant, Pinecone หรือ Weaviate เพิ่มเติม
Vector Database เกี่ยวข้องกับ RAG ยังไง
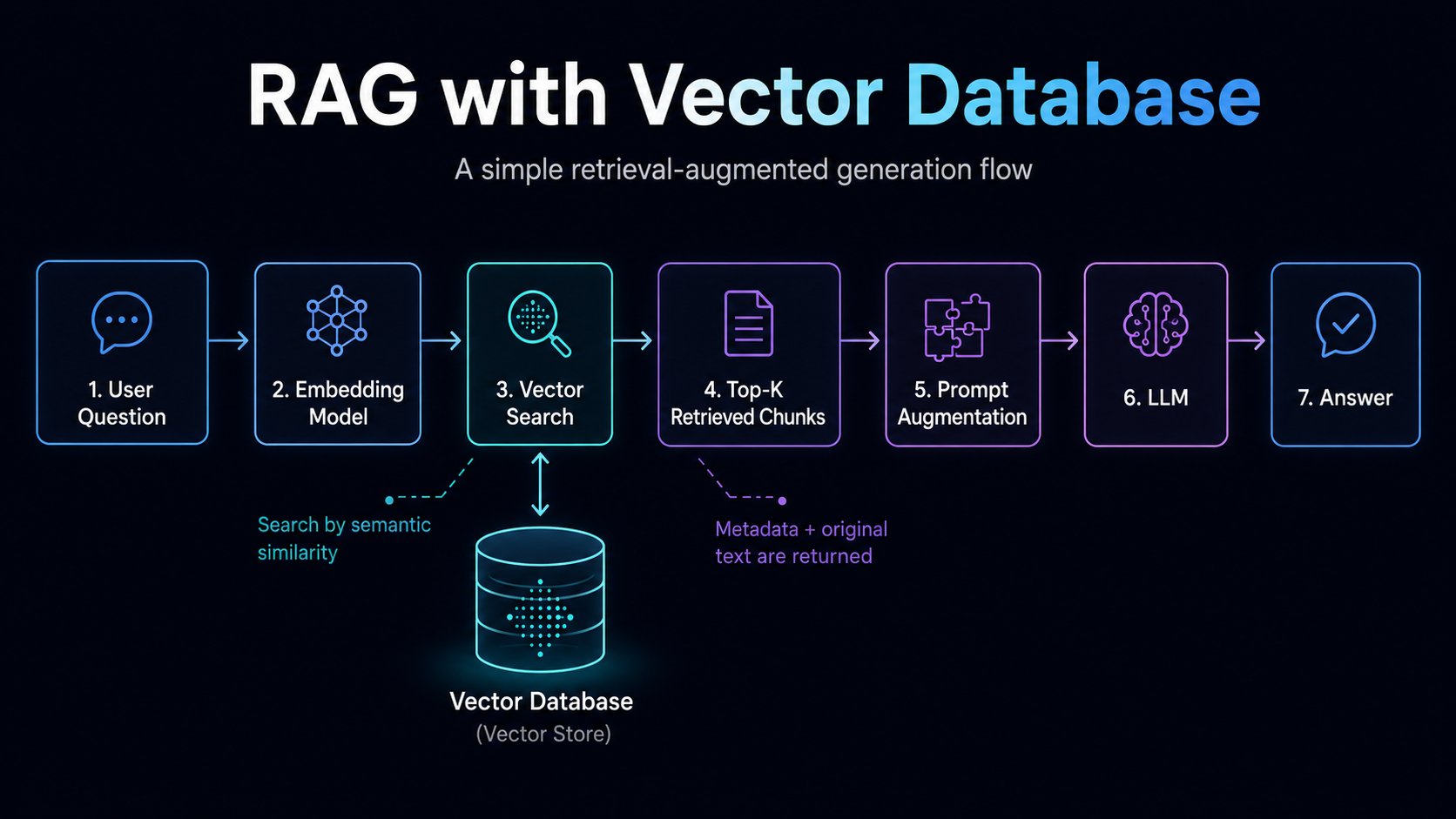
RAG หรือ Retrieval-Augmented Generation คือการให้ AI ไปดึงข้อมูลที่เกี่ยวข้องก่อน แล้วค่อยตอบคำถามจากข้อมูลนั้น
Vector Database มักเป็นหนึ่งในส่วนสำคัญของ RAG เพราะมันช่วยค้นหา context ที่เกี่ยวข้องกับคำถามของ user
Flow แบบง่าย ๆ คือ
1. เตรียมเอกสารหรือข้อมูล
2. แบ่งข้อมูลเป็น chunk
3. แปลง chunk เป็น vector embedding
4. เก็บ vector และ metadata ลง Vector Database
5. User ถามคำถาม
6. แปลงคำถามเป็น vector
7. ค้นหา chunk ที่ความหมายใกล้เคียงที่สุด
8. ส่ง chunk เหล่านั้นให้ LLM เป็น context
9. LLM สร้างคำตอบจาก context ที่ดึงมาได้
ถ้าเปรียบเทียบง่าย ๆ
LLM ปกติ = ตอบจากความจำ
RAG + Vector DB = เปิดหนังสือหาข้อมูลก่อนตอบ
นี่ช่วยลด hallucination ได้ เพราะ AI ไม่ได้ตอบจากความจำอย่างเดียว แต่ตอบจากข้อมูลที่ระบบค้นมาให้
ทำไม Metadata สำคัญมาก
เวลาเราเก็บข้อมูลลง Vector Database เราไม่ควรเก็บแค่ vector อย่างเดียว
เราควรเก็บ Metadata คู่ไปด้วย เช่น
- ข้อความต้นฉบับ
- ชื่อไฟล์
- URL
- document id
- page number
- category
- created date
- permission
เพราะ vector มีไว้สำหรับค้นหาเชิงคณิตศาสตร์ แต่ metadata มีไว้บอกว่า “สิ่งที่ค้นเจอคืออะไร”
ใน RAG หลังจากค้นเจอ vector ที่ใกล้เคียงแล้ว เราต้องเอาข้อความจริงจาก metadata หรือ document กลับไปใส่ใน prompt ให้ LLM
ดังนั้นผมมองว่า
Vector = ใช้หา
Metadata = ใช้อธิบายว่าสิ่งที่หาเจอคืออะไร
ถ้าไม่มี metadata ระบบจะรู้แค่ว่าพิกัดนี้ใกล้กับคำถาม แต่ไม่รู้ว่าจะเอาข้อมูลจริงอะไรไปให้ LLM ตอบ
ตัวอย่าง Use Case
1. Semantic Search
ค้นหาข้อมูลจากความหมาย ไม่ใช่ keyword
เช่น ค้นคำว่า “สุนัข” แล้วเจอข้อมูลที่ใช้คำว่า “หมา” ได้
2. Image Search by Text
ถ้าใช้ model แบบ multi-modal เช่น CLIP เราสามารถใช้ข้อความค้นหารูปภาพได้
เช่น พิมพ์ว่า
fox dog
แล้วระบบค้นหารูปที่มีความหมายใกล้เคียงกับคำนี้ออกมา
3. RAG สำหรับเอกสารภายในองค์กร
เช่น ระบบถามตอบจากเอกสารบริษัท คู่มือระบบ หรือ policy
User ถามคำถาม ระบบค้นหาเอกสารที่เกี่ยวข้อง แล้วส่งให้ LLM สรุปคำตอบจากข้อมูลจริง
ข้อควรระวัง
Vector Database ไม่ใช่ว่าใส่เข้าไปแล้วระบบจะฉลาดทันที ยังมีหลายเรื่องที่ต้องออกแบบดี ๆ
1. ต้องใช้ Embedding Model ให้สอดคล้องกัน
ตอนเก็บข้อมูลกับตอนค้นหาควรใช้ Embedding Model เดียวกัน
ถ้าเปลี่ยนโมเดล พิกัดของข้อมูลอาจเปลี่ยน ทำให้ค้นหาผิดหรือไม่เจอข้อมูลที่ควรเจอ
2. ผลลัพธ์อาจไม่ exact 100%
การใช้ ANN ช่วยให้ค้นหาเร็วขึ้น แต่ผลลัพธ์อาจเป็นค่าประมาณ
ต้องเข้าใจ trade-off ระหว่าง speed กับ accuracy
3. Metadata ต้องออกแบบดี
ถ้า metadata ไม่พอ เวลา retrieve เจอข้อมูลแล้วอาจไม่รู้ว่าต้องอ้างอิงกลับไปยัง source ไหน หรือ filter ข้อมูลยังไง
4. Performance ต้องคิดตั้งแต่ต้น
ถ้าข้อมูลเยอะมาก ต้องคิดเรื่อง indexing, storage, latency, batch ingestion และการเลือก database ให้เหมาะกับงาน
5. ไม่จำเป็นต้องใช้ Vector DB ทุกกรณี
ถ้าข้อมูลเป็น structured data ชัดเจน เช่น transaction, order, user profile หรือ report บางประเภท SQL อาจเหมาะกว่า
บางระบบอาจใช้ hybrid approach คือใช้ SQL filter ก่อน แล้วค่อยใช้ Vector Search กับข้อมูลที่เหลือ
ถ้าย้ายจาก ChromaDB ไป Qdrant หรือ Pinecone ต้องเปลี่ยนเยอะไหม
Concept หลักยังเหมือนเดิม
สิ่งที่ยังเหมือนกันคือ
- สร้าง collection หรือ index
- เพิ่ม document, vector และ metadata
- query ด้วย vector
- ดึงผลลัพธ์ top-k
สิ่งที่ต้องเปลี่ยนคือ
- SDK หรือ library
- syntax ของคำสั่ง
- connection config
- API key หรือ infrastructure
สิ่งที่ต้องระวังที่สุดคือ Embedding Model
ถ้าย้าย database แต่ใช้ Embedding Model เดิม ข้อมูลยังอยู่ใน vector space เดิม และผลลัพธ์ควรยังใกล้เคียงเดิม
แต่ถ้าเปลี่ยน Embedding Model ไปด้วย อาจต้อง re-embed ข้อมูลทั้งหมดใหม่
มุมมองของผมในฐานะ Backend Developer
สำหรับผม Vector Database ไม่ใช่แค่ database อีกตัวหนึ่ง แต่มันเป็น component สำคัญของระบบ AI สมัยใหม่
Backend Developer ยังมีบทบาทสำคัญมาก เพราะต้องออกแบบหลายส่วน เช่น
- data ingestion pipeline
- chunking strategy
- embedding process
- metadata design
- retrieval logic
- permission filtering
- prompt construction
- monitoring และ performance
ถ้า retrieval ไม่ดี ต่อให้ LLM เก่งแค่ไหน คำตอบก็อาจผิดได้
ดังนั้นสิ่งที่ควรเข้าใจไม่ใช่แค่ “ใช้ ChromaDB ยังไง” แต่คือ “จะออกแบบระบบค้นหาข้อมูลที่เกี่ยวข้องให้แม่นและใช้งานจริงได้ยังไง”
สรุป
Vector Database คือฐานข้อมูลที่ใช้เก็บและค้นหาข้อมูลจากความหมาย โดยอาศัย Vector Embedding และการวัดความใกล้เคียงของข้อมูล
มันเป็นส่วนสำคัญของระบบ AI หลายแบบ โดยเฉพาะ RAG ที่ต้องดึงข้อมูลจริงไปให้ LLM ใช้ตอบคำถาม
สิ่งที่ควรจำคือ
Vector Database ไม่ได้มาแทน SQL เสมอไป
แต่มันช่วยเติมความสามารถด้าน Semantic Search ให้ระบบ
สำหรับ Software Engineer หรือ Backend Developer ผมคิดว่า Vector Database เป็นเรื่องที่ควรเริ่มศึกษา เพราะในอนาคตระบบจำนวนมากอาจไม่ได้มีแค่ API + Database แบบเดิม แต่จะเริ่มมี AI layer ที่ต้องค้นหา context จากข้อมูลจริงก่อนตอบหรือทำงานต่อ
และ Vector Database ก็คือหนึ่งในพื้นฐานสำคัญของ layer นั้น